Et voilà ça commence à mettre des memes dans les newsletters, bravo le professionnalisme…
Pour cet épisode, vous avez le droit à deux biais pour le prix d’un ! Il se découpe en deux parties :
Cette semaine, je vous explique l’expérience à laquelle vous avez participé. Vous entendez tout le temps parler d’études scientifiques, vous allez enfin comprendre comment elles sont construites !
La semaine prochaine, on présentera les applications de ces biais dans la vie quotidienne (ainsi que les mécanismes de défense adaptés).
Commençons par les définitions.
N’oubliez pas de vous abonner pour recevoir les prochains biais, chaque Lundi à 18h !
1- Biais d’ancrage : La Définition Officielle™
Le biais d’ancrage est le fait de se reposer sur les informations déjà connues pour faire une estimation. Par exemple, lors d’une enchère ou d’une négociation, le premier prix annoncé va influencer les surenchères.
2- Lois de Weber-Fechner : La Définition Officielle™
Ces lois expliquent (entre autre) que pour différencier deux stimuli, nous avons besoin d’une grande différence relative, peu importe la différence absolue. Par exemple, il facile de différencier un arbre d’1 mètre d’un arbre de 3 mètres. Par contre il est difficile de différencier un arbre de 20 mètres avec un arbre de 22 mètres. La différence absolue est la même (+2 mètres) mais la différence relative est très petite (+10% contre +200%).
Comment l'a-t-on VOUS les avez démontrés expérimentalement
Dans la newsletter sur le biais de confirmation, je vous avais demandé de répondre à une question sur la lumière du Soleil. Certains s’en sont douté, c’était un piège pour tester le biais d’ancrage😈
Si on demande le temps que met la lumière du Soleil pour arriver sur Terre à des non-connaisseurs, les estimations seront plus hautes si il y a un grand nombre dans la question en guise d’exemple, et plus basses si le nombre est petit.
Étape 2/6 : lister les conditions de l’expérience
Cette étape est très importante pour deux raisons :
les scientifiques qui voudraient reproduire l’expérience pourront le faire dans les mêmes conditions
les lecteurs peuvent s’assurer que la démarche scientifique a été respectée
Dans une newsletter sur les biais cognitifs, les participants (des internautes) ont pu répondre à une question sur le temps de trajet Soleil->Terre. Chaque internaute répond à un seul des trois questionnaires suivant, choisi aléatoirement : un sans ancre (sans chiffre), un avec une ancre basse (nombres bas, 10 et 50), et un avec une ancre haute (nombres hauts, 10’000 et 50’000). Voici les formulations :
GROUPE 1 : Pas d’ancre (contrôle)
GROUPE 2 : Ancre Basse
GROUPE 3 : Ancre Haute
Étape 3/6 : former les groupes de participants
Dans toute étude scientifique digne de ce nom, il faut faire plusieurs groupes, dont un groupe contrôle. Un groupe contrôle, c’est un groupe sur lequel on ne va rien tester. Cela permet d’avoir des valeurs neutres, une base de référence. On peut ensuite vérifier que les résultats des autres groupes sont suffisamment différents du groupe contrôle. On dit alors que les résultats sont significatifs et pas simplement dus au hasard.
Par exemple dans les études médicales sur un nouveau médicament, un groupe contrôle sera le groupe auquel on donne l’ancien médicament, ou un placebo. Dans notre étude, le groupe contrôle sera celui qui reçoit le questionnaire sans ancre.
Il me fallait un moyen de rediriger aléatoirement les gens vers un des 3 questionnaires, en envoyant une seule newsletter… L’astuce ? Chaque caractère du lien renvoyait vers un questionnaire différent.
Étape 4/6 : traiter les données
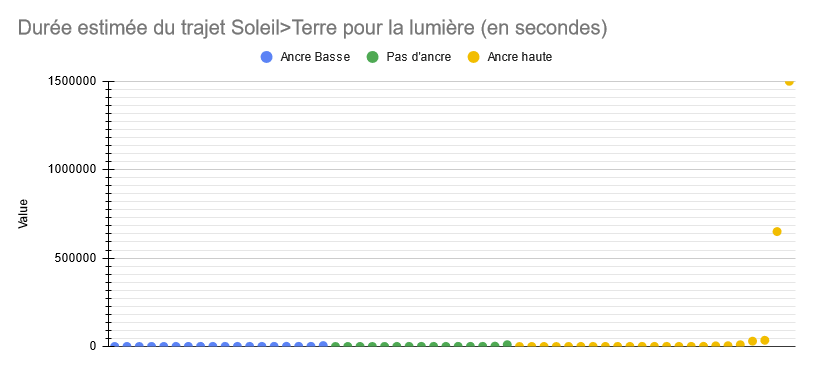
Voici le graphique des résultats :
- Heu… mais Aurélien, c’est nul !?
Ah… ah oui c’est… c’est pas fou… Bon…
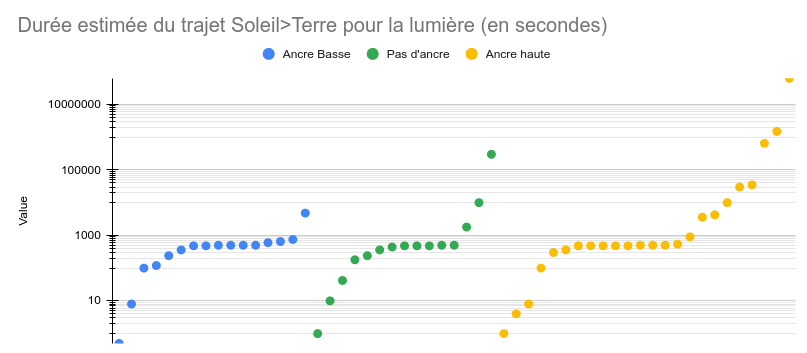
Bon, on annule tout, à la semaine proch NON ! J’ai une idée. On ne voit pas grand chose car les extrêmes écrasent le graphe. Dans ces cas là, on peut changer l’échelle pour que les grosses variations ne cachent pas les plus petites. Par exemple, on peut choisir une échelle logarithmique.
- Échelle logarithmique ..?
Sans rentrer des les détails, une échelle “normale” s’appelle une échelle linéaire, et pour passer à la graduation suivante, on additionne une quantité fixe (+100 par exemple). Sur une échelle logarithmique, pour passer à la graduation suivante, on multiplie par une quantité fixe (x100 par exemple).
Regardons ce que ça donne.
Ah, c’est bien mieux ! Petit problème : vous êtes bien plus compétents en astrophysique que je ne l’imaginais. Je ne m’attendais pas à ce qu’autant d’entre vous connaissent la vraie valeur. Cet échantillon est biaisé, et cela cause le plateau sur les courbes.
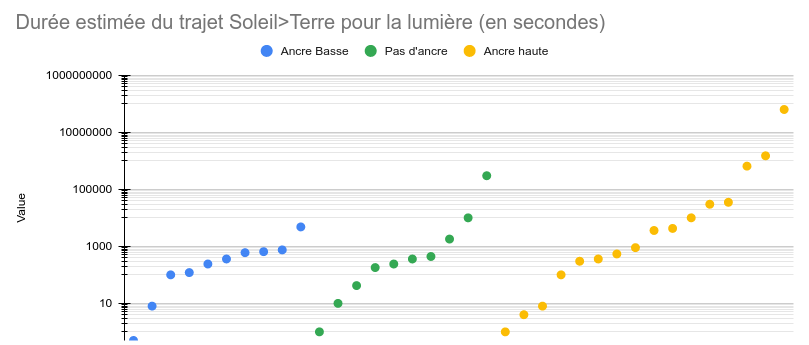
Je vais donc supprimer les points de données qui sont très proches de la bonne réponse (~499.8s, soit un peu plus de 8 minutes). Et oui, on a le droit de faire ça dans les études ! Tant qu’on explique pourquoi en tout cas😈
J’ai choisi de supprimer toutes les occurrences de “480” (beaucoup de gens ont répondu “8 minutes”, j’ai fait la conversion) et de “500”.
Étape 5/6 : valider ou invalider l’hypothèse de départ
On peut maintenant tester notre hypothèse : est-ce que l’ancre dans la question change quelque chose ? A l’œil nu, j’ai envie de dire que oui, mais je suis probablement en plein biais de confirmation. On peut être plus rigoureux grâce à un morceau de statistiques dont je vous épargne les détails. On va calculer la probabilité que la différence entre les courbes soit due au seul hasard. C’est ce qu’on appelle la p-value.
Résultat :
p-value = 0.0460
4.60% de risque que ça soit du pur hasard… Pas si mal non ? Vous pensez que je peux valider l’hypothèse initiale ?
Étape 6/6 : discussion critique
Les études se terminent toujours par une partie où les auteurs interprètent leurs résultats, proposent des explications, font leur auto-critique, émettent de nouvelles hypothèses etc.
Pour ma part, j’avoue, j’ai fait les calculs en me servant d’une hypothèse supplémentaire : vos réponses suivent leslois étendues de Weber–Fechner.
Heu… Weber c’est pas une marque de barbecue ?Ah mais attends, tu en as parlé au début… les arbres c’est ça ?
Bonne mémoire, c’est bien ça ! En particulier la loi de Fechner qui dit que l’intensité ressentie d’un stimuli suit une loi logarithmique. Et oui, l’échelle logarithmique du graphique, je ne l’ai pas sortie du chapeau. J’ai donc préféré faire les calculs de probabilité sur les logarithmes des valeurs plutôt que sur les valeurs initiales.
Sans utiliser les logarithmes, la probabilité que ces résultats soient dus au hasard atteint 30%. C’est très peu significatif. C’est en partie parce qu’on a peu de points de données, et que les réponses sont très écartées : elles vont de 0,5 à … 63’000’000 de secondes (2 ans).
- Bon, on la publie notre étude ?
Pas si vite !
Déjà, on a 4.60% de risque d’avoir obtenu ces résultats par hasard, ce qui est bien, mais pas top. On aimerait avoir une probabilité de <1%.
De plus, si on voulait se faire publier, on devrait passer par une étape de revue par les pairs, où d’autres scientifiques relisent, puis critiquent l’étude en se faisant l’avocat du diable (vous vous souvenez ? C’est pour éviter le biais de confirmation !).
Et dans notre étude, beaucoup de choses sont critiquables :
Avez-vous vraiment répondu au hasard ? Est-ce que vous avez pu communiquer / être influencé par d’autres lecteurs avant de répondre ?
Les données brutes sont-elles accessibles pour refaire les calculs ? (oui, ici 🙂)
Peut-on facilement reproduire l’expérience exacte, mais avec plus de participants ?
etc
Biais d’ancrage, lois de Weber-Fechner : concrètement, on s’en sert comment ?
C’est ce qu’on va regarder dans la partie 2 de cette newsletter. La suite arrive la semaine prochaine ! Allez, un peu de patience, elle est écrite depuis 1 mois et demi. Ce n’est pas si long une semaine par rapport à 1 mois et demi…
Merci d’avoir lu cette newsletter, que j’ai pris beaucoup de plaisir à écrire comme d’habitude. Si vous voulez recevoir un biais cognitif toutes les Lundis à 18h, inscrivez-vous ! Vous pouvez aussi liker / commenter / noter la newsletter pour qu’elle s’améliore 😉






")
")
")